Relay Operational Updates
Summary: We are making a couple of changes to the Bluesky relay servers this week. The wire protocol and semantics are not impacted, but the changes may impact firehose consumers:
- One way or another, the event stream sequence will change for all subscribers. Most consumers can probably just reset to the new cursor; see details below.
- The
bsky.networkhostname will be swapped to a new relay instance (with new sequence)
The atproto network is growing rapidly! This is exciting and positive, but it means we need to move up some of our network scaling plans. One particular resource bottleneck is the relay firehose. We are seeing sustained traffic of over 2,000 events per second, and we have hundreds of active consumers. Multiplied, the overall throughput is hard for any one server to keep up with.
We saw this problem coming from the beginning and we have several plans and options to mitigate it. Details for each of these are linked or in sections below.
First, we are simply upgrading the size of server that we run our primary relay instances on. We expect to do this in coming days. The main impact here will be a reset of the firehose sequence (including cursor values), which will impact all downstream consumers.
Second, we are introducing the concept of "firehose fan-out" services, and releasing our implementation Rainbow. These are servers which re-broadcast the event stream firehose to many clients, reducing the bandwidth load on relays themselves. Rainbow is now in production, as an implementation detail.
Third, we recently released Jetstream as a more informal and light-weight option for event stream consumption. We encourage developers to check out Jetstream, and switch over if it works for their use case.
We encourage folks to take advantage of Rainbow and Jetstream. You can run your own, or make use of our hosted instances. Some additional longer-term options are discussed at the bottom of this article.
We don't have a hard time or date estimate for the cursor sequence change, but we expect it this week, possibly tomorrow (Tuesday). We generally try to give more time and make changes less disruptive but we're not able to do so in this situation. Please follow the @atproto.com account, this blog, and in Github Discussions for announcements.
Relay Upgrade
The current Bluesky relay instance is available at wss://bsky.network. A more specific hostname for this relay instance will soon be relay1.us-west.bsky.network (not yet configured).
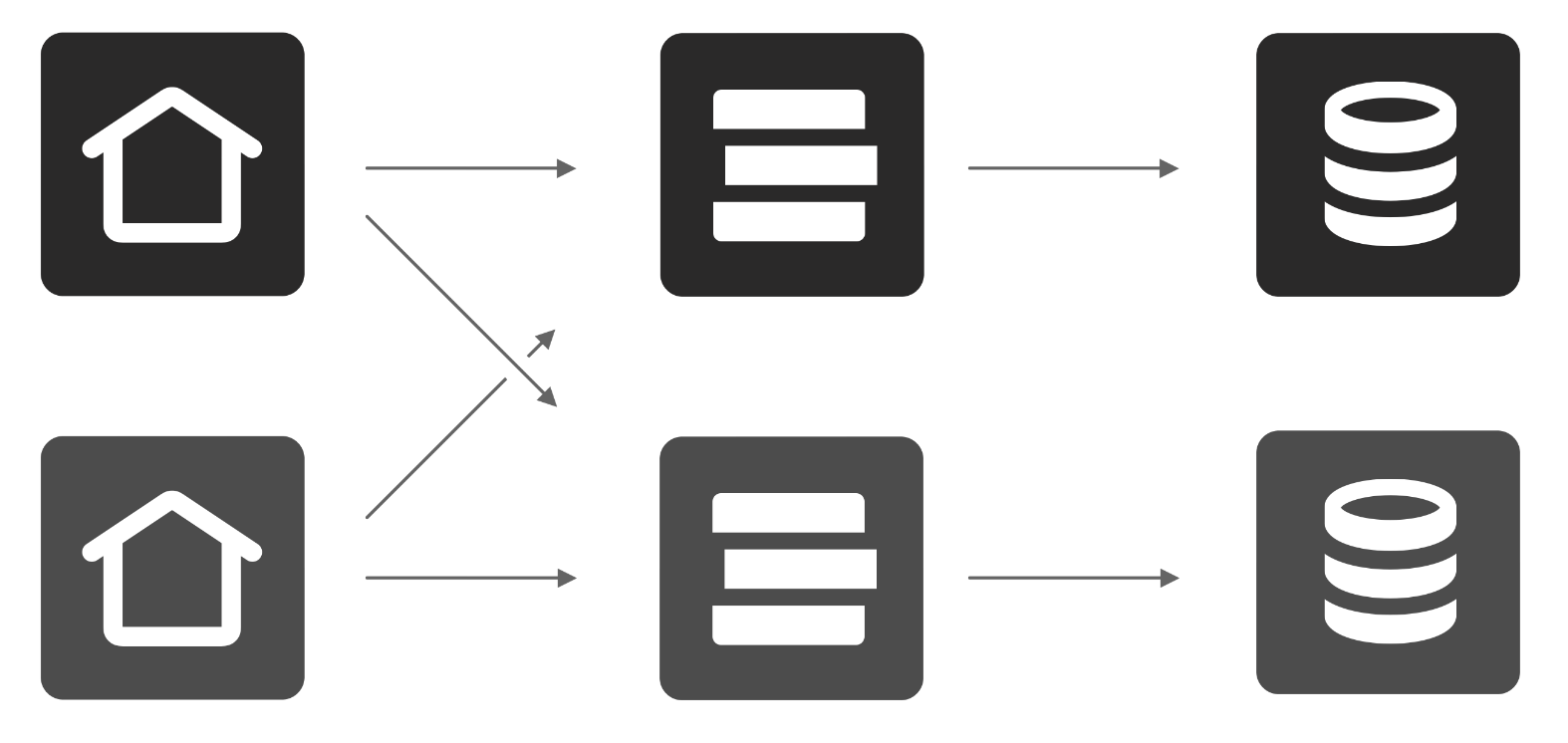
Instead of upgrading the relay in-place, we are going to start a new relay from scratch. This means that event stream ordering will be different and sequence numbers will not align with the current relay. This new instance will soon run at relay2.us-west.bsky.network (not yet configured).
There will be at least a short window when both relays are running, so downstream consumers can update their services to "cut over". At some point soon after the new relay is deployed, we will switch the generic bsky.network hostname to point at it.
What firehose consumers need to do about the cut over depends on how careful they need to be about processing every single event on the firehose.
Services which always connect to the firehose from the current offset don’t need to do anything. This includes developer tools like goat, and real-time sampling like Firesky.
Best-effort consumers can likely be configured to consume from the current firehose offset, and simply restart, missing at most a few seconds of events. This probably makes sense for feed generators, analytics, automated labeling, etc.
Services which want to really minimize the number of missed events can take a different approach. They can be programmed to connect to the new relay with no cursor, detect the current sequence number, then reconnect with a cursor a couple of minutes back (at current rates this means a few hundred thousand events back). This results in a time overlap window between the two relays (with some events processed twice), which helps minimize the chance of missing any events.
Firehose Fan-out and Rainbow
Firehose fan-out servers have a single upstream connection to a relay firehose, and re-broadcast that stream to multiple subscribing clients. They maintain a local backfill window (allowing re-connection with a cursor), but do not implement endpoints like getRecord or getRepo, only com.atproto.sync.subscribeRepos. They do not re-validate the event stream (eg, they don't verify signatures). They maintain the exact sequence numbers of the upstream relay, meaning that they are interchangeable with the relay and with sibling fan-out servers, and can be placed behind a load-balancer.
Today we are releasing Rainbow, a fan-out service implemented in Go. The source code is available in the indigo git repository, with the same MIT/Apache licensing as our other open source projects.
Rainbow is already running as part of our production relay deployment (wss://bsky.network), with our load balancer (haproxy) distributing WebSocket subscriptions to a separate server running Rainbow.
In the future, we may run additional Rainbow instances outside our primary data centers, similar to how we offer Jetstream instances today. This distributes network traffic over more routers, and could improve connection reliability and throughput for subscribers in regions outside North America.
Going forward, we recommend that software which consumes from firehoses (including atproto SDKs) support HTTP redirects for WebSocket connections. This enables "pooling" behavior where a single hostname could route clients to multiple distinct servers, without use of a load-balancer.
What Else?
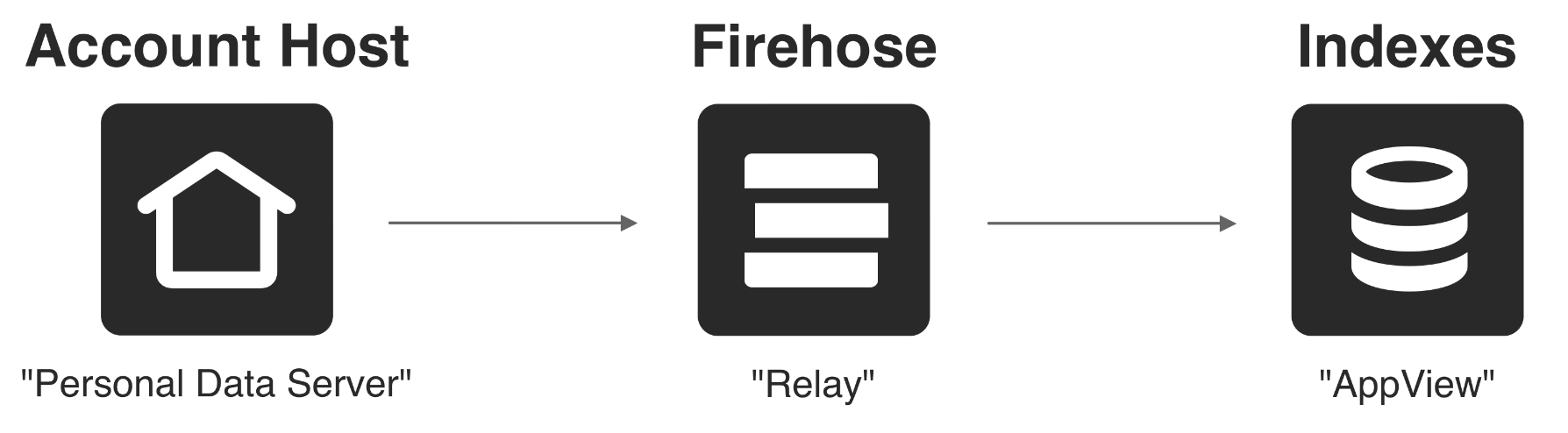
As a reminder, the relay synchronization API is the same as the PDS synchronization API, including the firehose. Relays are essential to the functionality of the atproto network: they are an operational and developer convenience, allowing consuming services to skip keeping track of which PDS instances are active.
A classic way to scale services like the firehose is sharding, where the stream is split into multiple parallel streams. atproto has a natural sharding key (the account DID), which means related events can be consistently routed to the correct shard. This will allow near-indefinite scaling of the firehose event rate, assuming compute and network resources are available.
Part of what makes relays difficult to operate at scale is that they function as both a "relay" (rebroadcasting events from PDS instances) and a full-network mirror (storing all repo contents). In the current protocol, it is necessary to combine both functions to fully verify repository operations, especially deletion of events. We think that clever implementations could make this work less resource intensive (for example, storing just record CIDs instead of full data). It is also possible to validate most aspects of the event stream without a full copy of the repo tree, and there could be a role in the network for "non-mirroring" relays.
Lastly, there is a particular need for efficient consumption and backfill of full-network content for only content and accounts which make use of specific record types. For example, “only whtwnd blog post records”, or “only accounts with labeling service declarations”. We are planning new features to make this type of network subscription and backfill much more efficient.